Understanding Observability
Defining Observability
Gartner defines observability as “the development of supervision into a process, with a view to providing an overview of digital business applications, accelerating innovation, and improving the customer experience.” A major factor in the No-Code scalability!
The Essence of System Observability
System observability involves identifying undesirable behaviors, such as service unavailability, errors, and sluggishness. It revolves around understanding the system’s behavior, detecting anomalies, and comprehending the reasons behind these anomalies, ideally before they impact customers.
Data Collection for Observability
Observability relies on collecting three types of data: detailed event logs, granular information on resource usage, and application traces.
Real-world Example of Observability in No-Code
An illustrative example of observability in a no-code environment is when a field in Airtable gets deleted during automation in Make. Observability allows the detection of potential errors before launching the Make scenario.
Challenges in Implementing Effective Observability
Implementing effective observability is complex, involving challenges like lack or excess of information, data silos, and issues with correlation. Understanding the correlation between collected data and its context is crucial.
The Power of Observability in Complex Environments
In complex and interconnected environments, observability excels at detecting weak signals. When coupled with artificial intelligence algorithms, it can identify potential incident scenarios and their sources, providing increased control over systems.
Rapid Deployment of Observability Data
The key to success lies in the rapid deployment of observability data. Having uniform access to all data, along with the ability to filter, aggregate, and visualize it, enables quicker and more efficient implementation of corrective actions.
Improvement of performance
While observability allows you to react effectively in emergency situations, this visualisation can also be used to improve the general performance of the system. Detecting instances of very high resource consumption (CPU, data volume…), implementing improvement processes, being able to predict future requirements so as to sustain the growth of your platform – there are many advantages.
At a time when digital transformation is accelerating, observability has now become necessary in order to achieve and maintain agility, speed, and performance, with a view to meet users’ ever-rising expectations.
Observability in no-code
State of play
Some no-code tools already offer monitoring and alert functionality (see table below). Monitoring is limited to simply displaying when an anomaly occurs. Observability allows you to understand the cause of this anomaly.
Nowadays the majority of tools interconnect with one another. So as to offer a complete stack, covering all expected functionalities – this is what gives them their development capacity. However, this interconnection between tools generates significant complexity! A minor change in the name of a field in a database can have knock-on effects on an entire application. The fragmented views available in each of the tools are not sufficient to enable effective observability.
Comparison of a number of tools regarding their level of observability:
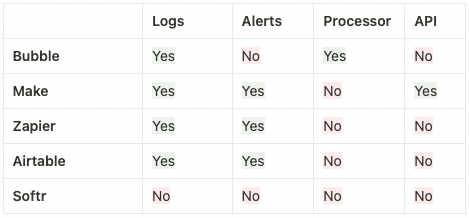
Often, the performance of these tools is not yet at the desired level, however, progress is being made. Let’s take the tool Make (formerly Integromat), as an example. When applying any change to an automation, you’re able to retrieve previous version thanks to the API. Previously, the necessary provisions had to be implemented in order to address this flaw.
At present, this essentially involves adopting a proper system of documentation and good working practices, to ensure that you correctly grasp the implications of each change. In particular, you must ensure that transverse process mapping and data exchange between the tools are taking place. This involves a high level of manual labour and requires a great deal of discipline in terms of keeping the system up to date. We have now compiled a list of good documentation practices. However, these are far from ideal on account of their complexity of application.
You will have gathered that we are still a long way from achieving the goal of observability. At best, what we currently have amounts to supervision/monitoring.
Why must the observability of no-code be improved?
In order to be capable of managing a growing influx of users, to understand the use of resources, and to offer high quality and a competitive level of service: these are the essential elements if we are to scale things up.
There is still a way to go in order to bring no-code environments to the desired level of robustness. In addition to observability, the management of production and test environments, version control, release management, and many other aspects must as yet be improved.
With no-code editors having raised more than 4 billion dollars globally in 2021, it is safe to say that this field is progressing rapidly. We will be making our own contribution, with ncScale, through our Monitoring solution.
Credit: Photo by Luke Chesser on Unsplash